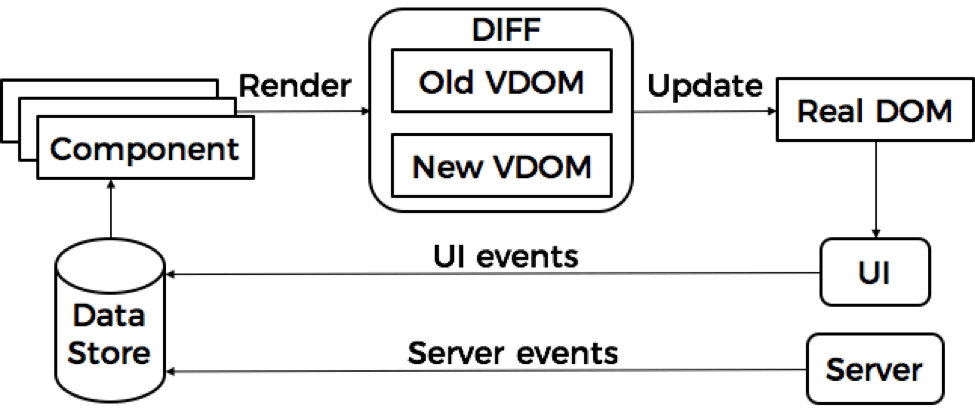
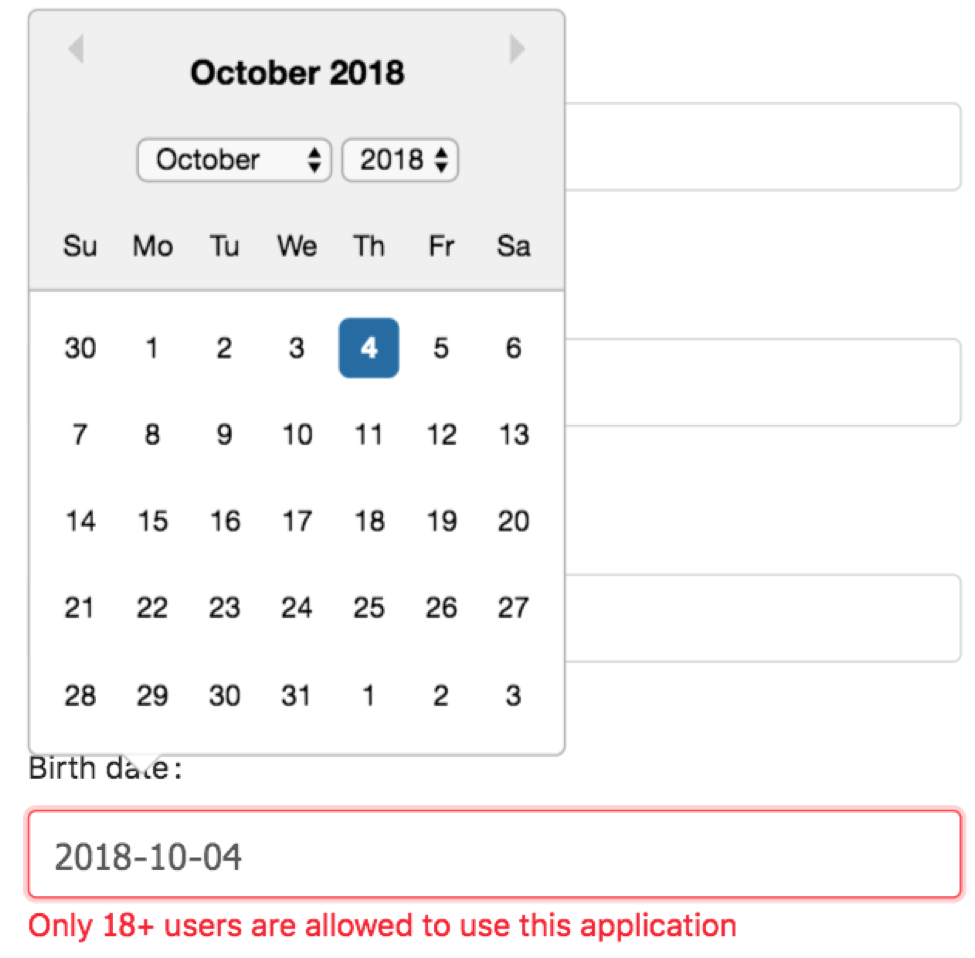
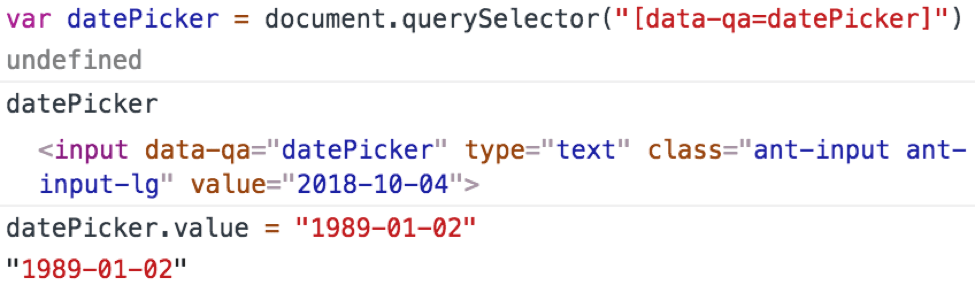
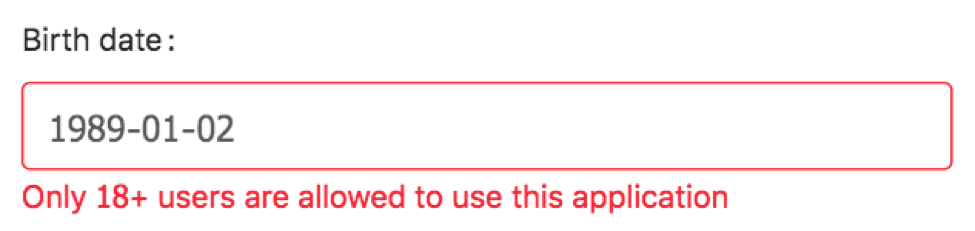
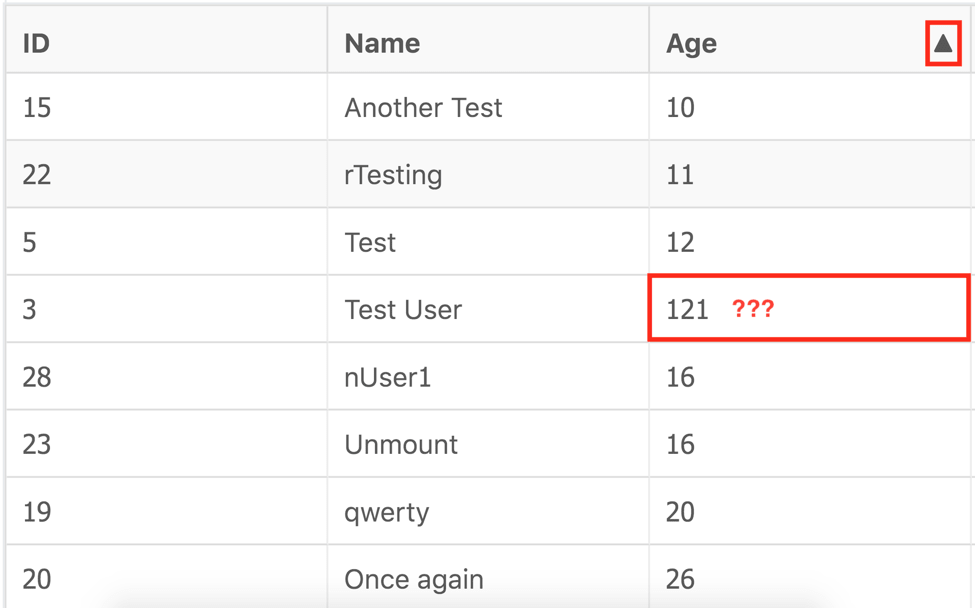
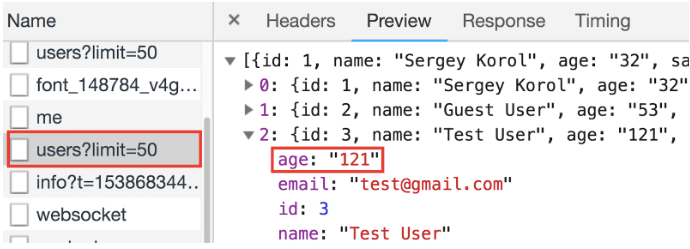
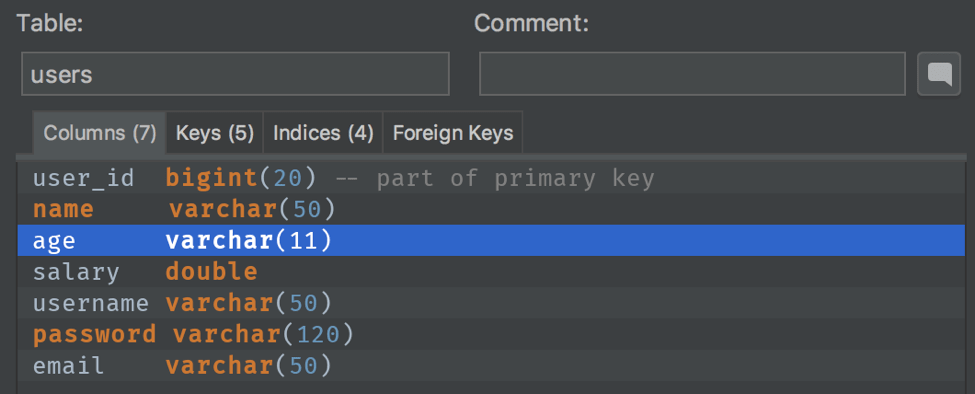
So what about the automation? It’s very important to keep the balance between simplicity and versatility, so that no matter what column you’re passing as input, your test will know exactly how it could be sorted, and moreover, how to check a sorting order depending on the types we’re working with.
@Test(dataProvider = "sortingData")
public void recordsShouldBeSortable(final Column column) {
open(LoginPage.class)
.loginWith(User.dummy())
.sort(column, ASC);
verifyThat(at(GridPage.class)).recordsAreSorted(column, ASC);
at(GridPage.class)
.sort(column, DESC);
verifyThat(at(GridPage.class)).recordsAreSorted(column, DESC);
}
@DataSupplier
public StreamEx sortingData() {
return StreamEx.of(AGE, SALARY);
}
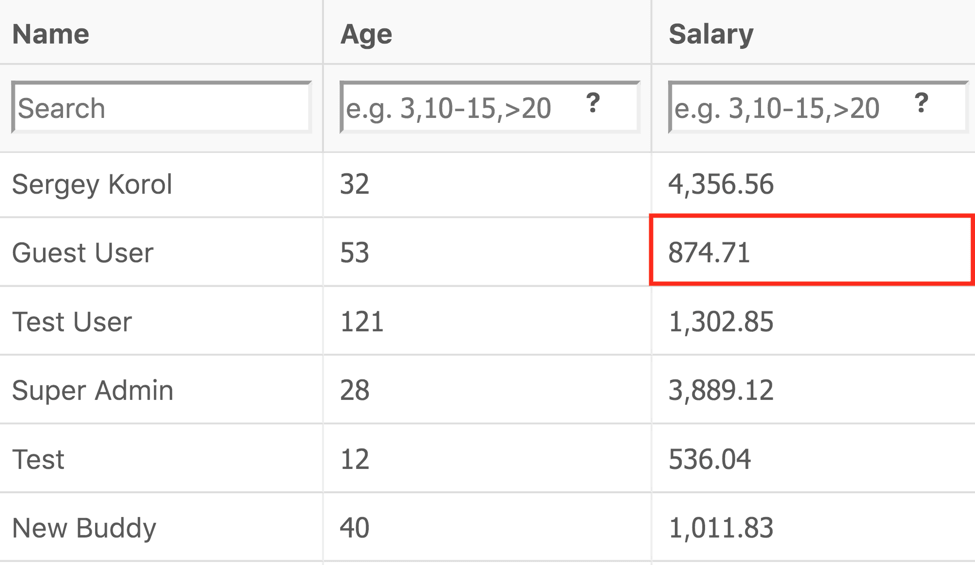
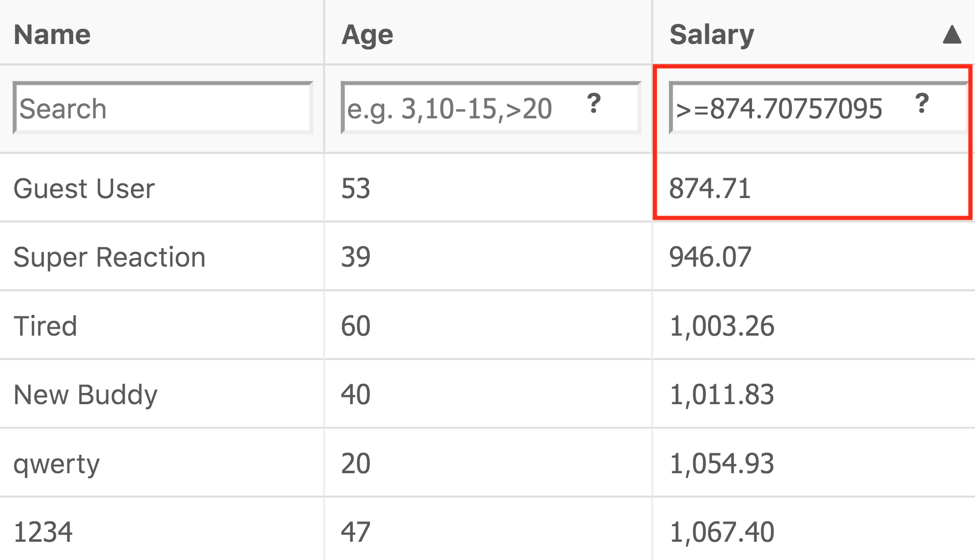
The similar situation is with filtering. A test must be flexible enough to work with any column, operator and value type.
@Test(dataProvider = "filteringData")
public < T > void recordsShouldBeFiltered(final Column column, final Operator < T > operator, final T value) {
open(LoginPage.class)
.loginWith(User.dummy())
.adjustColumn(column)
.expandFilter()
.filterBy(operator, value);
verifyThat(at(GridPage.class))
.recordsMatchCondition(column, operator, value);
}
@DataSupplier(transpose = true)
public StreamEx filteringData() {
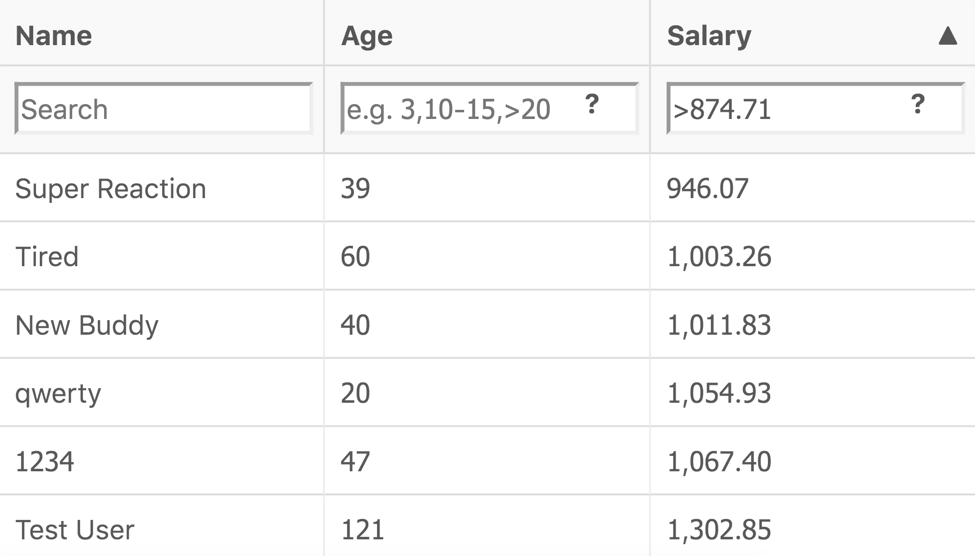
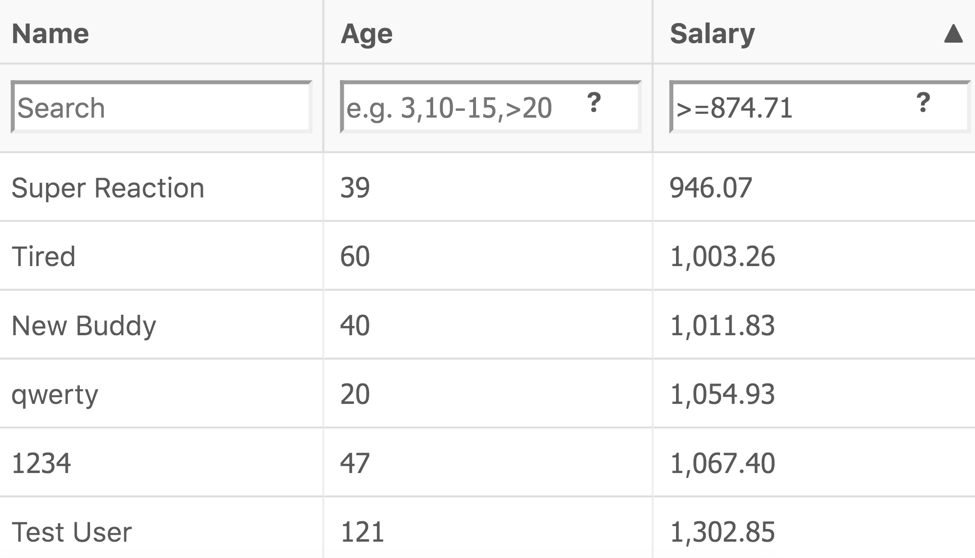
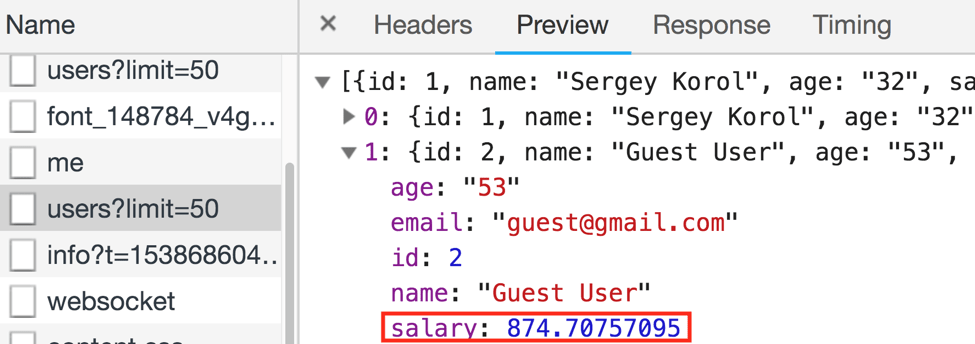
return StreamEx.of(SALARY, GREATER_OR_EQUAL, 874.71);
}
You may just be wondering, how we could achieve such conciseness and flexibility? In one of my Selenium Camp talks, I demonstrated the way of Selenium ExpectedConditions encapsulation behind simple enum values. This same technique could be applied to Grid columns:
@Getter
@RequiredArgsConstructor
public enum GridColumn implements Column {
AGE(Column.TO_INT, NumericFilter.class),
SALARY(Column.TO_DOUBLE, NumericFilter.class);
private final Function < String, ? > valueMapper;
private final Class < ? extends Filterable > filter;
@SuppressWarnings("unchecked")
public < T extends Filterable > T getFilter() {
return (T) use(filter, this);
}
public String getName() {
return name().toLowerCase();
}
}
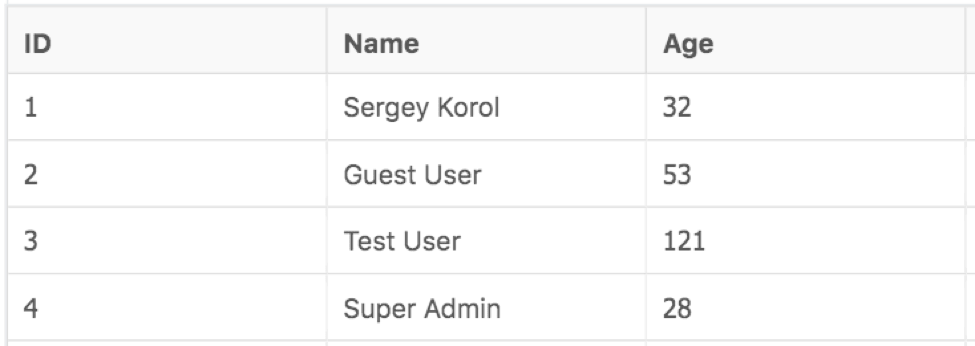
Tests or data providers may operate with some obvious names like AGE, SALARY, etc. But each column will know for sure which types it should work with, and how to convert Strings to the required data type. That’s very important since the Selenium testing framework gives us Strings. And we can’t operate raw Strings in the context of such tricky columns as AGE and SALARY. Otherwise, we’ll replicate the same issue, which we’ve just uncovered on the backend. Moreover, we’ll hide the real bug of the application!
The situation with operators is a bit trickier as we have 2 different representations of the same thing on UI and in the code. For humans it’s obvious to use operators like >, <, >= or <=. But the machine won’t be able to understand it, as it’s just a symbol. We can’t say: “Hey, Java Stream, here’s a >= symbol, take care of everything else”. So the only valid option is to teach our program, what this sign means in terms of data processing. And it also could be implemented with a help of enums:
@Getter
@RequiredArgsConstructor
public enum DoubleOperator implements Operator<Double> {
EQUAL("", Double::equals),
GREATER(">", (ob1, ob2) -> ob1.compareTo(ob2) > 0),
LESS("<", (ob1, ob2) -> ob1.compareTo(ob2) < 0),
GREATER_OR_EQUAL(">=", (ob1, ob2) -> ob1.compareTo(ob2) >= 0),
LESS_OR_EQUAL("<=", (ob1, ob2) -> ob1.compareTo(ob2) <= 0);
private final String value;
private final BiPredicate<Double, Double> filter;
}
Such mappings allow keeping our code clean and flexible so that we could easily integrate a complicated data processing logic directly into the streams or assertions by request.
And don’t forget about the root cause analysis! It opens up some great new opportunities in terms of testing.