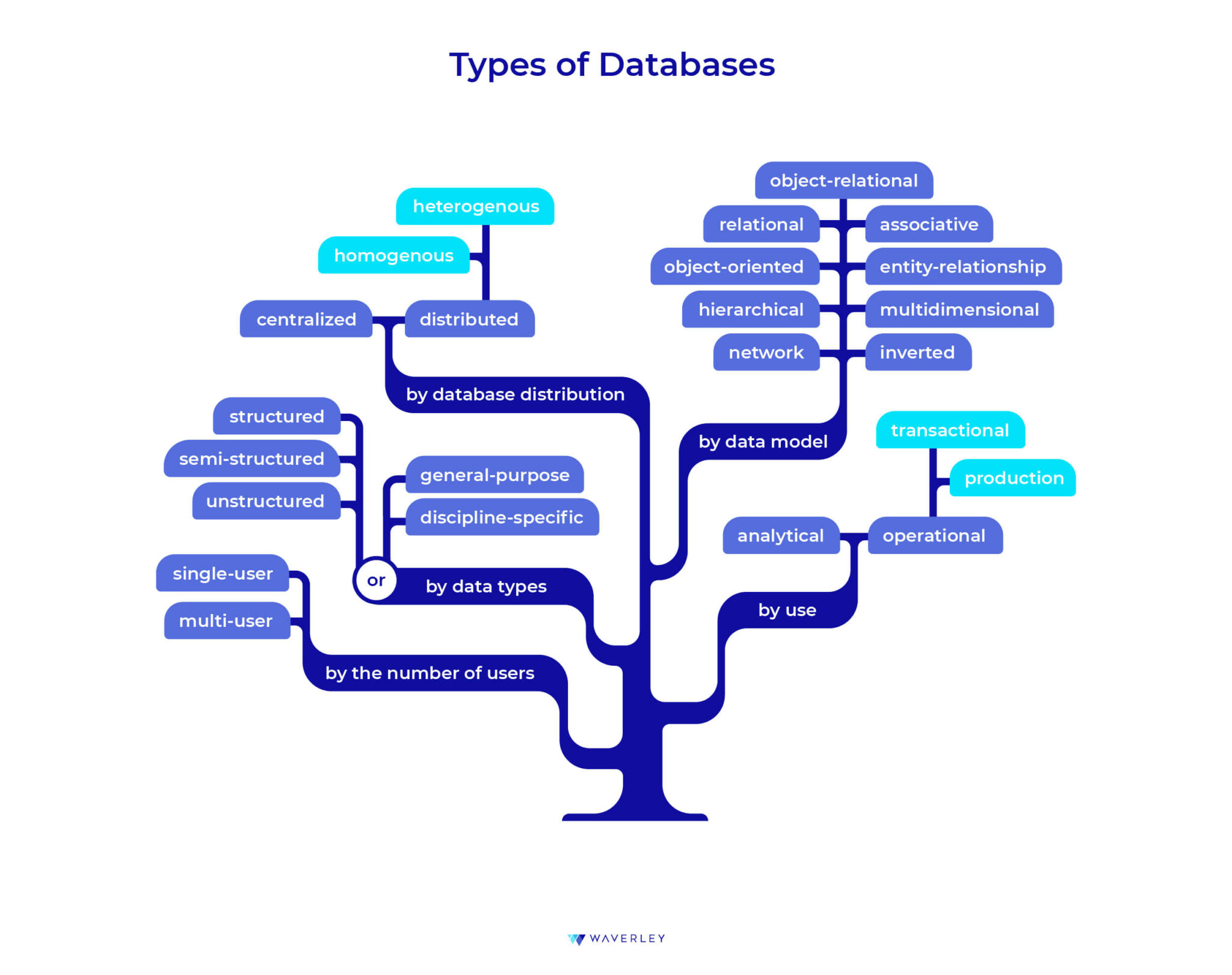
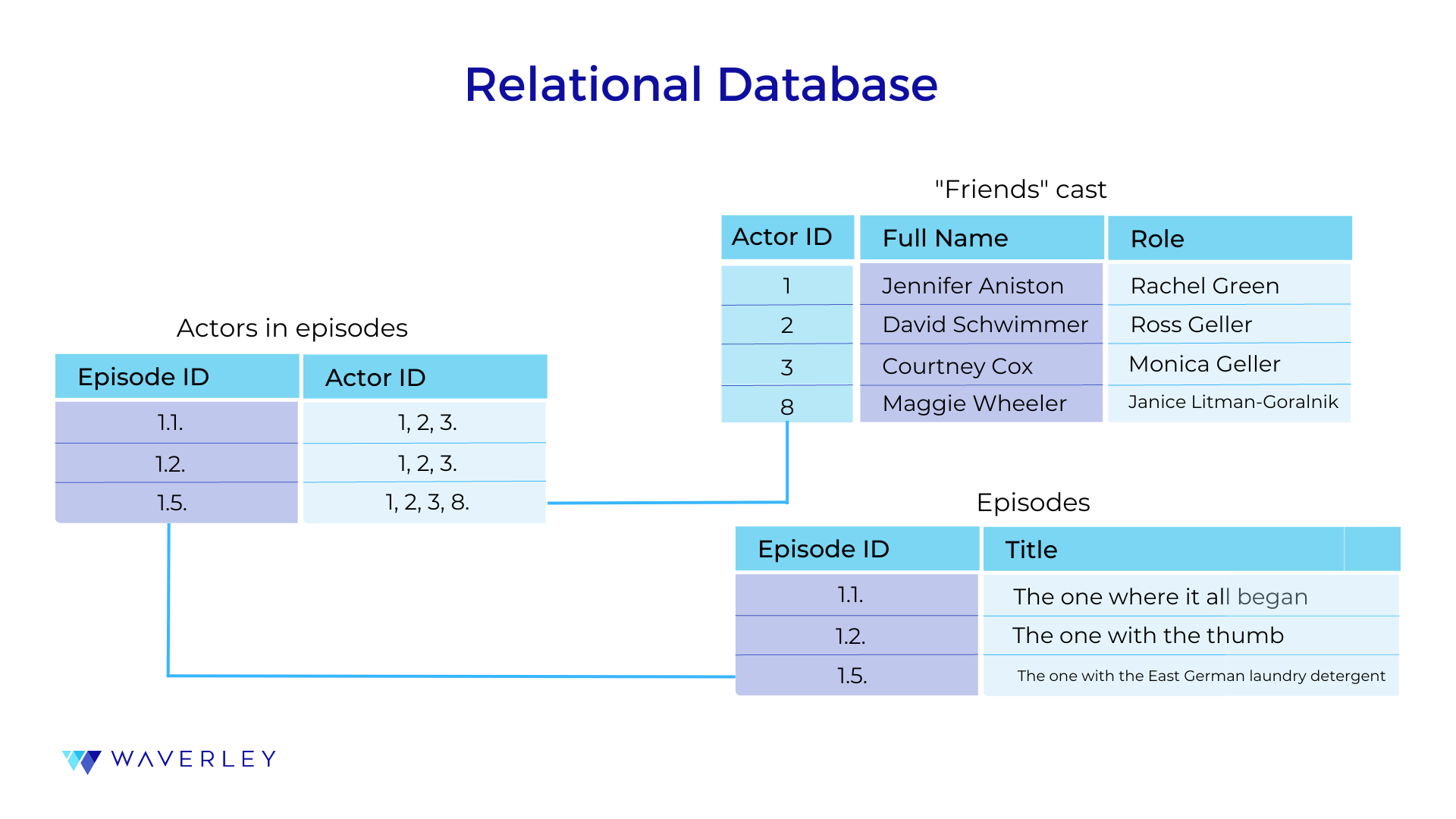
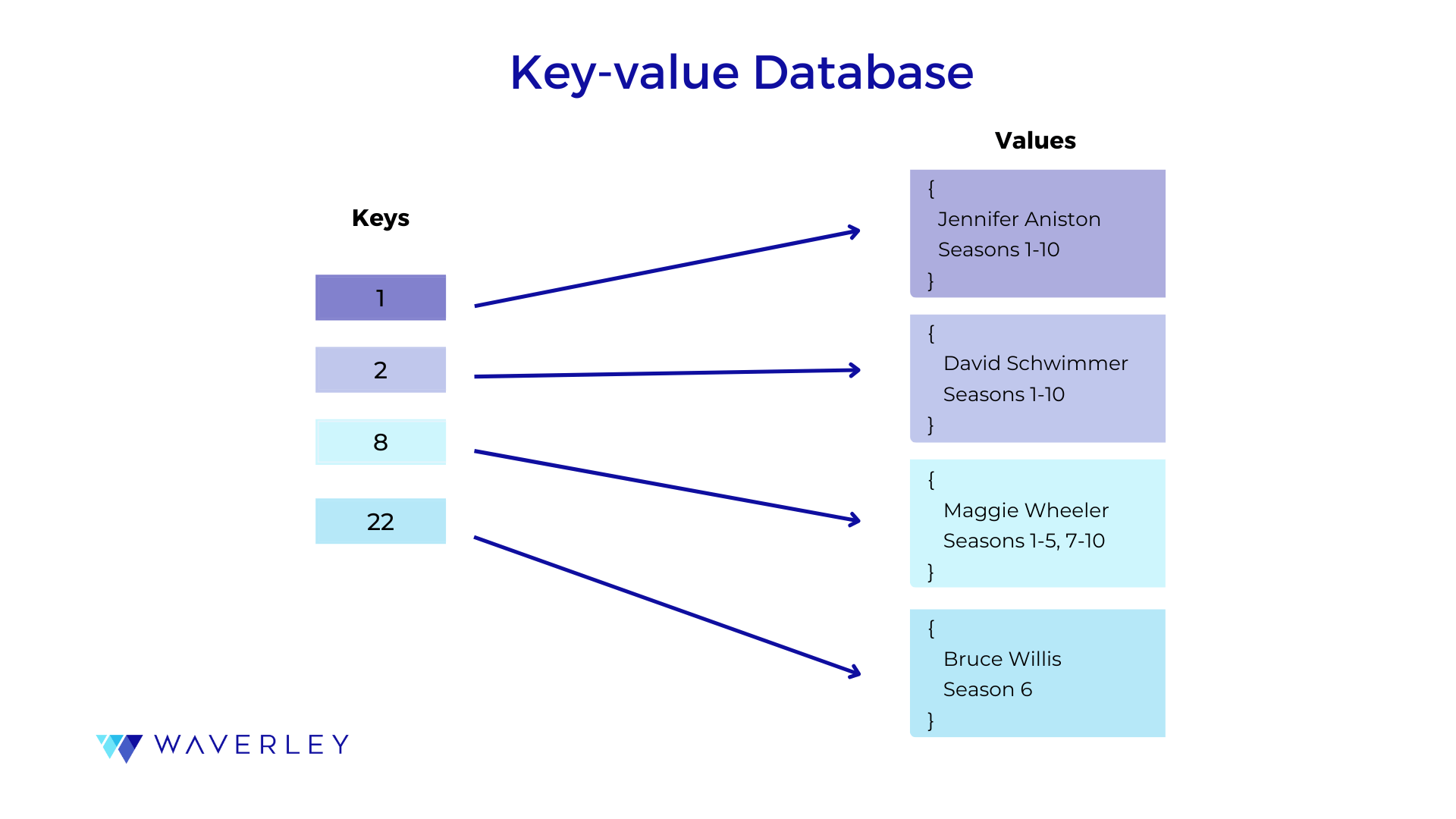
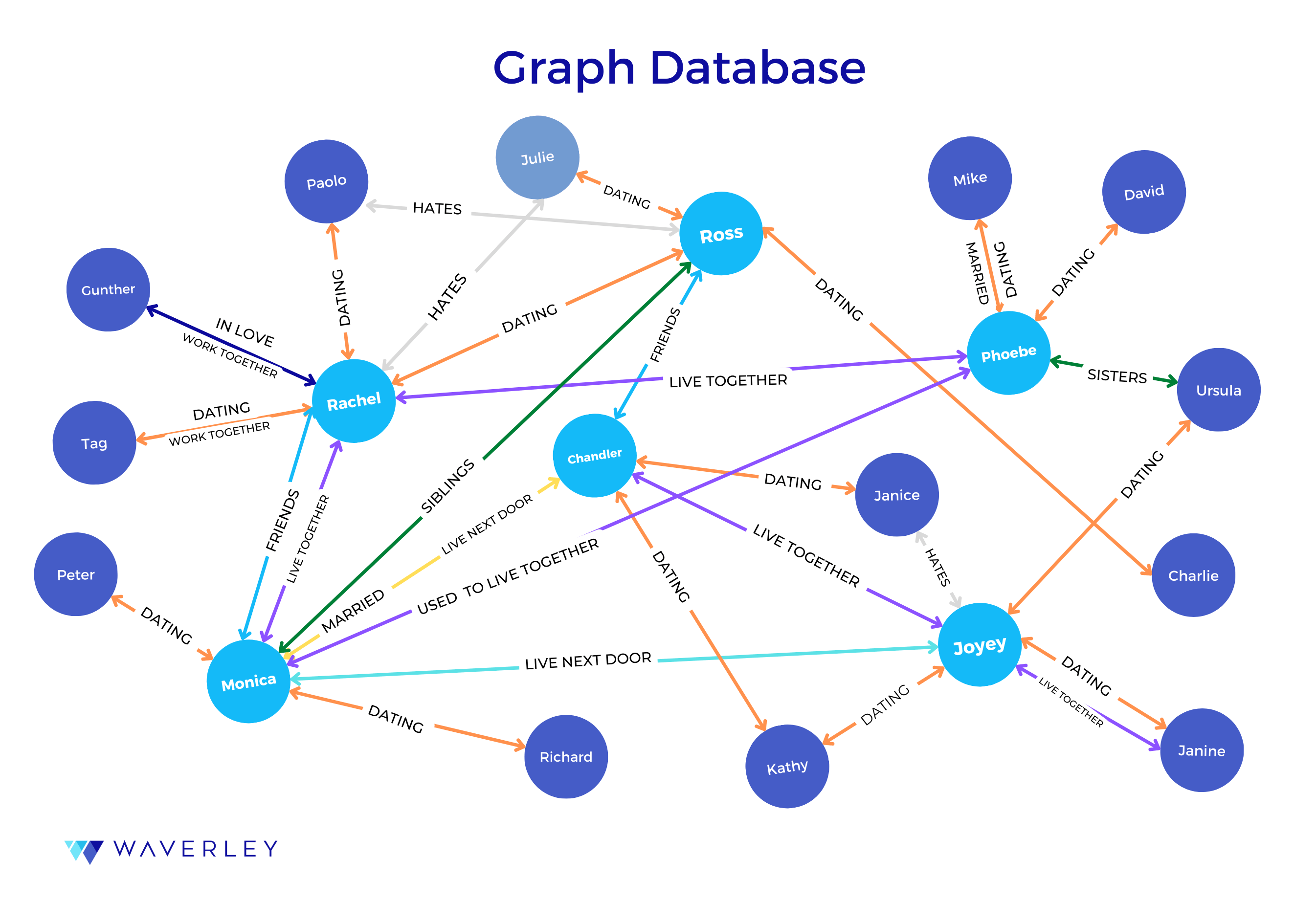
Another important thing is the approach we take when creating an index for a row and how complicated our queries can be. This will affect our database’s scaling capabilities. At the initial development stage, the choice of the database might look quite simple – just choose a database taking into account what type of data you will work with and how you are going to structure it.
But as you move on with your app development trying to add new features, new kinds of data, new user roles, and trying to scale, you might witness as your development has suddenly turned into a headache. For example, our choice is Cassandra, which is a NoSQL columnar database type. If, according to new product requirements, we need to make a complex query to collect all data, we will face a bottleneck as this database is not fully suitable for complex queries with various additional conditions.
Or let’s take MongoDB and start building links between its different collections in the code. We can take a relational database and rest on the fact that our object has 15 options for details, and in order to have a normalized database, we will have to create 16 tables and decide which one to write the details from the code. You can argue that in the new version of relational databases there is a JSON column type. But here you can’t make an index on the field inside it, and writing a request for filtering on it is still a pain in the neck (however not impossible). Another option is to consider the CQRS approach when we have 2 repositories. But, again, this will solve some of our problems – and also add new ones.
So how to choose a database in this case? To solve this dilemma, it’s worth considering the following aspects:
- Are we dealing with big data?
If yes – go for Cassanda or HBase which are both non-relational and columnar, and allow you to make column-based queries efficient for working with big data. They are a great fit for OLAP-based systems, thus being applicable for analytic purposes. - Read or write operations?
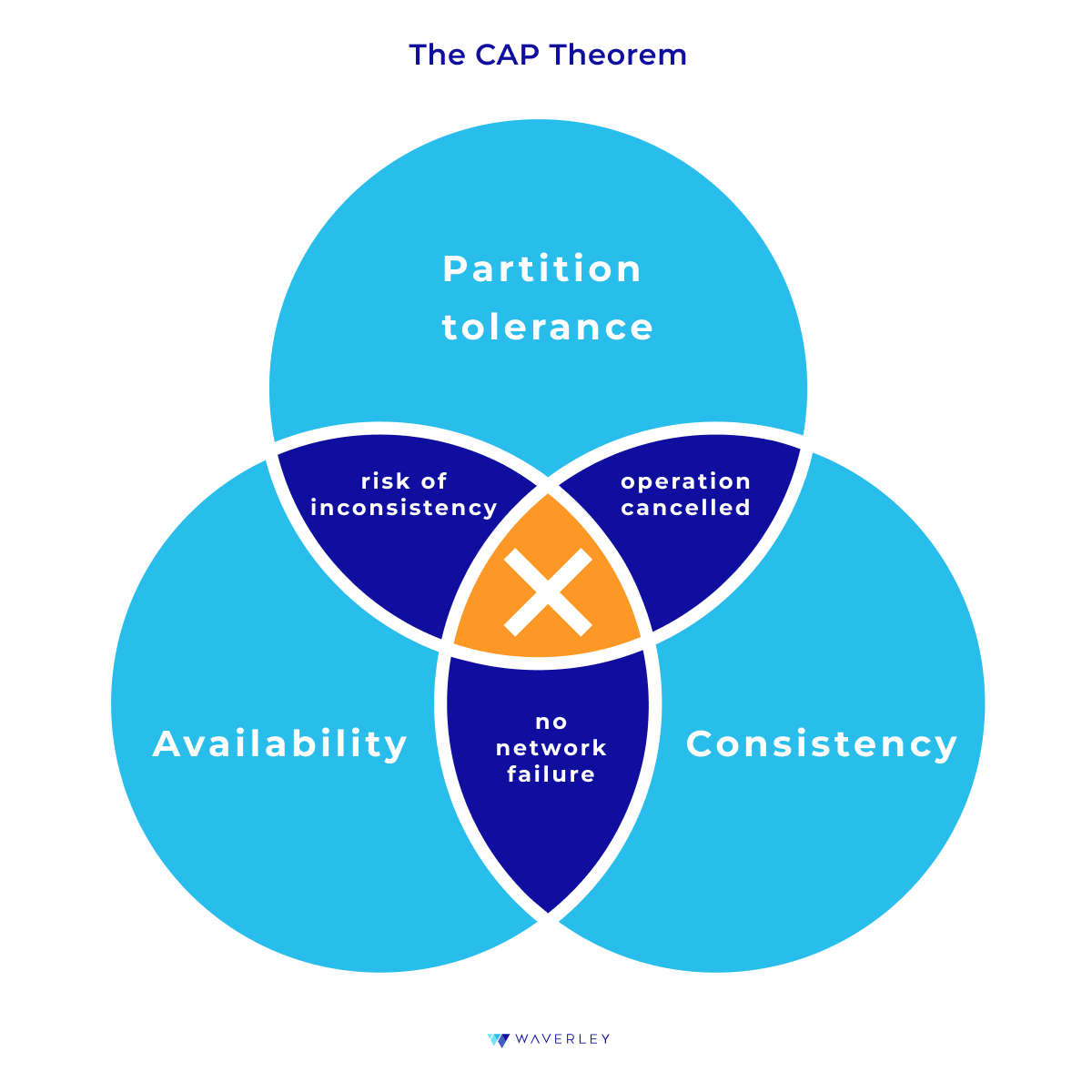
In complex applications, different types of databases are not equally efficient in carrying out read and write operations. Also, each application will require a different ratio of read and write operations to be performed, as well as their complexity. Thus, we rely on the CQRS pattern – Command and Query Responsibility Segregation. This means we should have separate database query and command models in a system. For example, the NoSQL document-oriented MongoDB will be more convenient for writing data while the relational SQL database Postgres will be a good choice for querying for data. - How are your business objects structured?
A relational database is very suitable for working with structured data. However, if we deal with unstructured or semi-structured data, this also does not mean that we can only consider NoSQL databases. After all, don’t forget about the JSON cell type in Postgres. What can influence our choice here is the performance of your database considering the size, complexity, and schema of your data.
Performance
When we speak of database performance, we can mean several interrelated characteristics of databases. First of all, performance is about the time it takes for a database to pass a query – latency. The lower the latency – the faster a read or write operation goes through. The influencing factors here are network connection and query complexity.
A way to impact network connection to reduce latency is by hosting our application closer to our database, in the same region, for example. As for the query complexity – it’s closely related to the data types and schemas we are using and how “compatible” they are. For example, we can expect low latency from a relational database when handling two-dimensional data that fits well into a row-column order. But once we need to process more data dimensions, our data transactions may get too hard for an RDBMS to operate fast. In such a case, we can shift our attention to NoSQL.
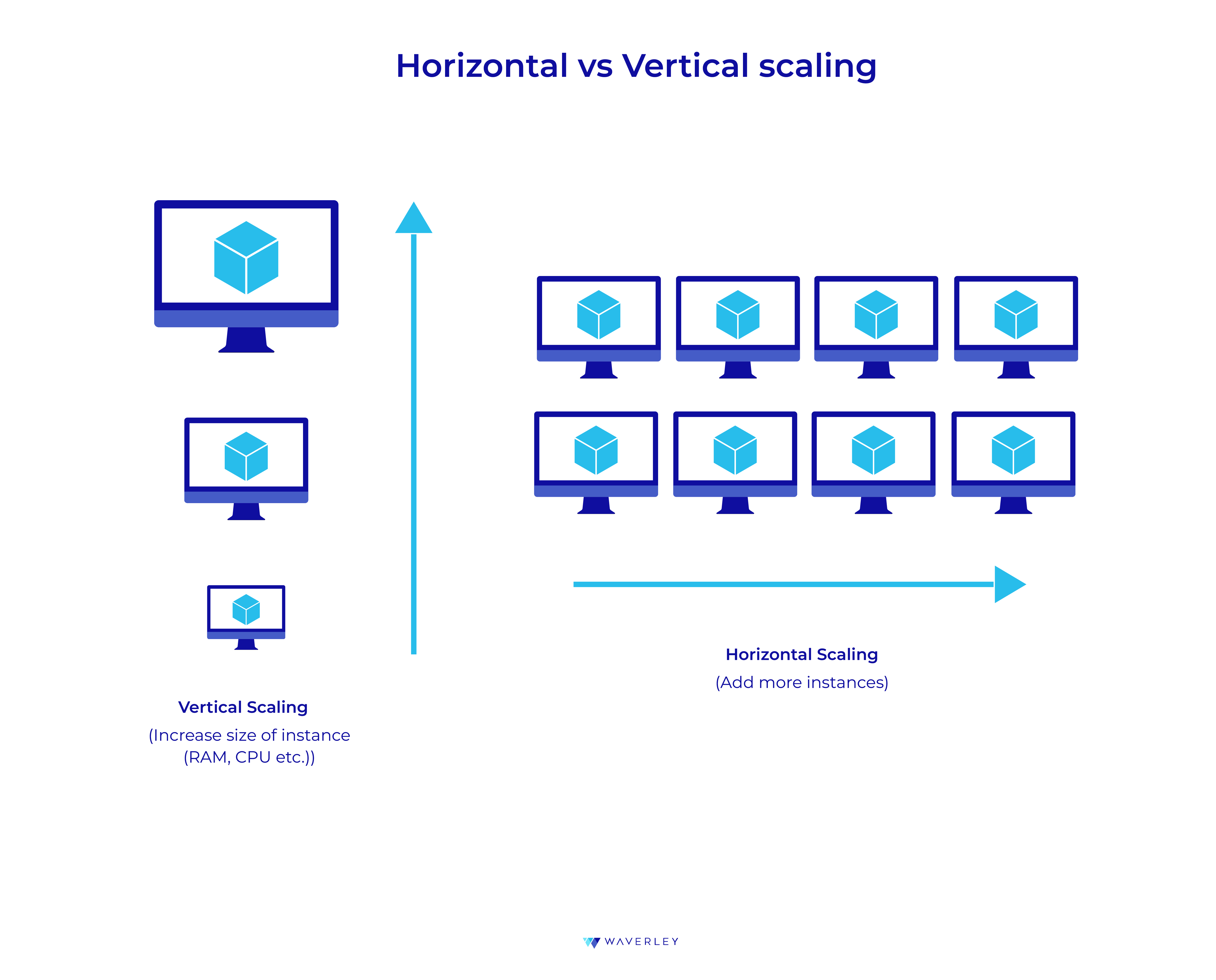
Another aspect affecting database performance is transaction rate, also known as throughput. The higher the throughput a database can handle, the more users can simultaneously query it without hurdling the speed of processing. Apart from software and hardware features which directly impact a database throughput, we can take into consideration the workloads to be dealt with, for example:
Are these frequent but small transactions as in an oline banking app or less frequent but bulky ones, as in a recommendation engine?
– OLTP-based databases are designed to handle such workloads well. Go for a highly-structured SQL or a key-value database that runs in-memory.Does a transaction include any data sorting, filtering, search by keywords, or other modifications?
– Wide-column databases are designed in a way that allows less resource consumption and better data compression.Will the workload depend on a region, time of the day, season of the year?
– Database distribution across more clusters can help spread the unexpected workload bounces evenly and save performance.
Are you more certain now about which kind of database could be more suitable for your web or mobile app? We hope you are. But this is not it!