Embedded AI Systems: A Guide to Integrating ML in Embedded Systems

Contents
We are well used to the idea that AI systems are powerful and, behind the scenes, require bulky high-performance computing resources such as supercomputers or clusters deployed locally or in the cloud. To work properly on smaller devices like regular desktops, mobile phones, or smartwatches, they make use of an internet connection.
Whereas in many cases ensuring stable connectivity is not a problem or immediate system response is not critical, in real-time systems, such as autonomous vehicles or smart healthcare wearables, every millisecond counts and can be life-changing. To avoid connectivity limitations, these systems must be able to process the data and figure a response directly on board. Thus, such systems that are capable of handling certain Machine Learning workloads on board are referred to as Embedded AI systems.
Understanding the Concept of Embedded AI Systems
By definition, an embedded system is a computer system, i.e. a combination of a processing unit, memory, and input/output, that performs specific functionality as a part of another mechanical or electronic system. For example, embedded systems can be the elements of small handheld devices such as remote controls as well as bigger ones such as home appliances, vehicles, and even industrial assembly lines.
Embedded vs General-Purpose Systems
In comparison with general-purpose computers, embedded systems could be much smaller and cheaper in performing the same dedicated tasks, which made them very popular and applicable in many spheres of life, from consumer goods to aeronautics and the military. Also, we can see how embedded systems differ from general-purpose computers using this table:
| Embedded System | General-Purpose Computer |
|---|---|
| Special-purpose hardware | Generic hardware |
| Embedded OS for specific functions or no OS | General-purpose OS |
| Pre-programmed firmware and non-alterable by the user | Programmable by user |
| Real-time response and application-specific requirements are key | Performance and computing capacity are key |
| Perform limited tasks | Perform many various tasks |
| Little power consumption | More power consumption |
| Need less operational power and memory | Need more operational power and memory |
| Less complex and cheaper | More complex and expensive |
| May or may not have a GUI | Has a GUI |
| Only exist within other devices | Are self-sufficient |
The Use of AI in Embedded Systems
For many years now, embedded systems have been serving to help us turn simple mechanical and electrical devices into digital ones, adding some automation and tracking capabilities. A good example could be most modern cars, equipped with sensors and computers responsible for tracking engine performance, adaptive cruise control, or enhanced parking functions all helping drivers have a safer and more comfortable driving experience than their purely mechanical predecessors.
Meanwhile, one more step forward is the implementation of autonomous cars which, in addition to the multitude of enhanced functions, are capable of making real-time decisions based on their immediate environment, similar to how humans would. Such abilities of a vehicle as detecting and identifying obstacles, deciding whether to stop, go around, or backward, and defining the optimal driving speed in traffic based on road conditions and traffic rules are the results of the Machine Learning algorithms running within the embedded system of a vehicle.
| Feature | Older cars (up till 80-90-s) | Modern cars (1990-s-2010-s) | Autonomous cars (2010-s-now) |
|---|---|---|---|
| Speed tracking | Car system | Car system | Car system |
| Fuel level | Car system | Car system | Car system |
| Engine performance | Human | Car system | Car system |
| Parking | Human | Car system + human | Car system |
| Speed control | Human | Car system + human | Car system |
| Navigation | Human | Car system + human | Car system |
| Steering | Human | Human | Car system |
| Decision making | Human | Human | Car system |
In this case, the decision-making and similar functions that previously could only be trusted to a human are now performed by the embedded machine learning systems within the vehicle. Contrary to the use of general-purpose computers in the cloud or edge computing, where we would require some sort of wireless connectivity with the processing unit, with embedded ML all the ML processing is done directly on the vehicle. This helps ensure the system’s real-time performance, avoiding latency caused by data travel times and possible connectivity interruptions.
At the same time, the functionality of an embedded ML system still remains focused on the vehicle functions, and the computer system constitutes only a part of the entire vehicle mechanism. Users cannot install here a computer program designed for a general-purpose computer or tablet and the vehicle won’t start and drive without a car engine and other essential car parts. This is what makes it different from a desktop computer or a mobile phone system.
Embedded Systems and Artificial Intelligence
In the previous paragraph, we looked at what an embedded system is, its main characteristics, and how it can embrace ML capabilities. In this section, we will focus more on what Embedded AI (EAI) is and what makes the use of machine learning in embedded systems possible.
Benefits of Machine Learning in Embedded Systems
Based on the above use case, we can define the main advantages of using embedded systems to incorporate ML capabilities.
- Real-time processing: for systems where response time is vital, it may be too risky to rely on internet connectivity with the data processing unit residing in the cloud or an edge node.
- Cost savings: to deal with a limited range of narrow-focused tasks of a device, you can use a less complex and cheaper computing unit.
- Privacy and data security: the system collects and processes a variety of user data, a great part of which can be sensitive, such as users’ personal data, location, and voice recording. When data processing is done on board, without sharing it through the network, there’s no risk of privacy compromise.
- Design flexibility: with embedded systems, you can choose from a great variety of hardware form factors and pre-program the firmware specifically to your needs.
On the other hand, it is a well-known fact that ML workloads require substantial computing power. Can the less complex and powerful embedded system’s hardware ensure enough processing capacity to deal with ML tasks? To answer this question, we will have to look at AI in embedded systems from two different perspectives – the machine learning demands of hardware and how powerful the hardware on the market is. Let’s consider the ML needs first.
How Machine Learning Works
What is the core difference between ML and traditional algorithms? To put it simply, we can say that ML is a complexity of algorithms. More importantly, traditional algorithms and ML models are created using different inputs and underlying principles. A traditional algorithm is a kind of instruction, we define the rules of how the data should be processed to get a result and can predict the ways it will behave with different types of data.
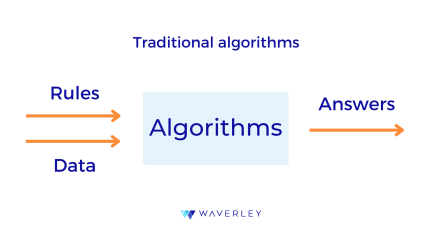
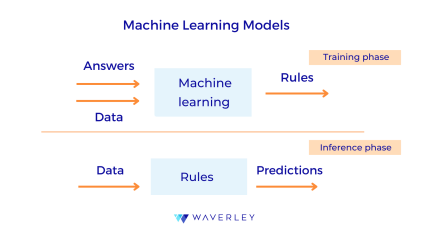
Meanwhile, the creation of an ML model is way more complex. It consists of two stages: training and inference.
At the training stage, we take a machine learning algorithm, for example, the Naive Bayes classifier algorithm, a k means clustering algorithm, or the support vector machine algorithm, and feed data to it which contains both input and results, for instance, the images of cats and dogs labeled as “cat” or “dog”. The task of the ML algorithm at the training stage is to define the rules of how this data is correlated that will be an ML model.
At the inference stage, we run a set of new but relevant data, e.g. new images of cats and dogs, through the model – the rules defined by the algorithm – to test whether the model can provide viable output in the form of predictions, decisions, object detection, etc.
Machine Learning Requirements
As we can see, at its core, an ML algorithm is a complex mathematical model that has to perform a large number of calculations using the training data. Speaking of deep neural networks, which are even more complex and consist of layers of ML algorithms, the number of calculations and parameters are counted in billions.
Thus, the training phase is the most computationally expensive task which requires a powerful computer equipped with a central processing unit (CPU) accelerated by the parallel processing power of a graphics processing unit (GPU) or a network of them. However, in the context of running machine learning on embedded systems, this task can be “outsourced” to a cloud computing platform and we can only connect to it from time to time to update the on-device model we speak of below.
The ML inference phase – that is running the model itself – may not require this much processing capability and already trained ML models can run on the device level. In addition, even very complex ML models can be optimized for running on constrained embedded device architecture or even on microcontrollers using specialized frameworks and tools also referred to as Tiny ML or Edge AI (e.g. TensorFlow Lite, AIfES) and model optimization techniques (network pruning, parameter quantization, knowledge distillation). This way, the simplest ML model’s memory footprint may get reduced to a few tens of kilobytes as well as low power and computing requirements that make them suitable for embedded networks, and devices that operate on battery power.

All in all, your ML requirements for hardware will depend on your model’s complexity defined by the nature of the model’s algorithm, the number of its features and parameters, accuracy, and speed, as well as the tasks it is designed for and amount of data it will have to process. The higher the figures, the more powerful hardware you’ll need.
The key metrics for measuring your ML model’s performance and complexity will include:
- Inference latency: This reflects the time it takes for the ML model to process a single input and produce an inference result. It is measured in milliseconds.
- FLOPS: The FLOPS indicates the number of inferences that the ML model can perform per second.
- Accuracy: This is the measure of the correctness of the predictions of the ML model compared with the ground truth or expected outputs. This represents the performance of the model for a given task.
- Power efficiency: This is the indicator of how effectively the ML model utilizes the device’s power resources, often in terms of the number of inferences per watt (inferences/watt).
You might want to refer for expert advice and professional machine learning development services to analyze your AI needs on a case-by-case basis and come up with some actual requirements in numbers.
Also, to better understand your project’s ML needs, you may consider answering the following questions:
- What specific tasks my ML model is expected to cover?
- What level of accuracy can satisfy my needs?
- Supervised or unsupervised learning?
- How much data will my system need to process?
- Will it be inference all the time or occasionally?
- How fast the model should provide the output?
Hardware for AI in Embedded Systems
As machine learning in embedded systems is covering more applications and growing in demand, hardware design companies are focusing their efforts on developing ML-optimized chips. In fact, the AI chip market is estimated to grow at a CAGR of 40.5% by 2030, reaching a worth of $227.6 billion, with NVIDIA, Intel, and Google investing heavily in this field of technology.

Key Considerations
Speaking of finding the right embedded hardware to handle AI workloads, it is important to pay attention to our device’s design, expected performance, and costs in conjunction with real-time processing needs, resource constraints, and the need for on-device intelligence.
Model Design
Such physical characteristics of a device as size, weight, and power consumption play a key role for EAI systems. Our edge device might have a wide spectrum of physical constraints, from lightweight palm-sized dimensions of a wearable to the size of an on-wall dashboard and bigger in-vehicle boards or enterprise-scale machines that pose much fewer physical restrictions. Power source needs and possible charging frequency will also vary, depending on whether your device will work on a battery supply or can be constantly connected to the grid. This is particularly important since computationally intensive tasks are highly power-consuming.
Performance
Hardware performance is the decisive factor when it comes to running your ML model as well as other system tasks, such as memory/power/tasks(scheduling) management, etc. The more powerful hardware you can fit into your device, the more accurate and complex ML model your can run on it and the more functionality can be added. However, one should be careful with the latter as more functionality also means more potential.
Cost
Of course, this characteristic is rather subjective and largely depends on your project’s budget and expected ROI. But the good news is that hardware providers offer a range of products and prices to choose from and balance your specific ML needs and available resources. Below, is an example of a hardware solutions series for embedded devices offered by Arm that have the computational power to cover dedicated embedded ML tasks.

The Components of Embedded AI Systems
As a rule, we aim to design an EAI system that will consume as little power and computation and is as fast and accurate as possible. Systems with higher performance and memory can perform more complex ML tasks at a greater speed but have high power consumption rates and are more costly. In this section, we take a look at the key embedded system elements:
- Integrated CPU and GPU that impact our system processing speed.
- Memory and system storage space define the system processing capabilities and space for data.
- Sensors that collect the external data needed for system interaction with the environment and that our AI model will process.
- System bus and drivers that ensure the interconnection of the system elements.
- Power supply options for embedded systems and artificial intelligence processing.
Processor and Accelerators
The first and most important task for an embedded systems and machine learning architect is designing the optimal processor core configuration to handle your specific AI inference workloads and other system management tasks. So choosing this type of hardware, take into account such factors as processing speed, power efficiency, and compatibility with machine learning framework. Here, we’ll shortly consider such types of processing cores as CPU, GPU, FGPU, and ASIC.
- CPU is the system’s general-purpose Central Processing Unit. It runs programs and applications on a computer device, the extract, transform, and load (ETL) processes, and works well with mixed data inputs, such as in systems that use both audio and text. Modern CPUs have multiple cores (commonly 4-16 cores). Their performance is measured in gigahertz (GHz).
- GPU is a Graphical Processing Unit dedicated to graphics processing due to its parallel cores. Because of the high number of small cores that handle parallel computation tasks, GPUs turned out to be of great use for AI workloads, both model training and AI inferencing. Thus, they are used for high-performance computing but also have a larger memory footprint and higher power consumption than CPUs.
- FPGA is a Field-Programmable Gate Array – an integrated circuit that can be reconfigured by users to meet specific use case requirements when a high degree of flexibility is required. Same as GPUs, FPGAs can run multiple functions in parallel and can even assign parts of the chip for specific functions and thus are much more performant in executing AI models compared to CPUs. As an advantage over a GPU, FPGA’s architecture ensures memory is closer to the processing which helps reduce latency and power consumption. On the other hand, this is a more expensive hardware option.
- ASIC is an Application-Specific Integrated Circuit – a computer chip that combines several different circuits on one chip, a “system-on-a-chip” (SoC) design type. Unlike FPGA, it is designed to perform a certain fixed function by the manufacturer (like the MTIA ASICs, and Apple’s Bionic chip) and cannot be reprogrammed. It provides low power consumption, speed, and a small memory footprint but is more expensive and only suitable for mass production. Custom ASICs examples include VPUs – Vision Processing Units designed for image and vision processing (Intel Movidius VPU), TPUs – Tensor Processing Units first developed by Google and optimized for its ML framework TensorFlow (Google Coral Edge TPU), and NCUs – Neural compute units developed specifically for AI-related tasks at a lower power level (Arm’s ML processor Ethos-55).
This table is the comparison of the main core types features, their advantages and disadvantages:
| Core Type | Cost | Features | Benefits | Constraints |
|---|---|---|---|---|
| CPU | Low to medium |
| Good at running complex instructions and tasks |
|
| GPU | Medium | -Parallel computing tasks for graphics rendering |
|
|
| FPGA | Medium to high |
|
|
|
| ASIC | High |
|
|
|
| VPU | High | Simpler architecture designed for parallel vector operations |
|
|
| TPU | High | Custom, integrated chip, optimized for the TensorFlow framework |
|
|
| NPU | High | Designed to accelerate the processing of neural networks | can be integrated into CPUs, GPUs, or ASICs, or can be standalone chips |
|
Memory
For embedded systems and AI workloads, it is important to choose the needed type and size of memory for storing models and intermediate data. In an embedded system, memory hierarchy takes a huge portion of both the chip area and power consumption. Thus, system designers strive to optimize the memory hierarchy in a way that will reduce hardware usage and energy consumption but will sustain high performance at the same time.
Like other computer systems, embedded systems need a combination of different memory types, each responsible for enabling specific system functions:
- RAM (Random Access Memory): its main function is dynamic data storage during program execution, including variables and stack data. It’s fast but volatile, meaning it doesn’t retain the data when the system power is off – that’s why it’s important for your system to have a power supply that will cover its energy consumption needs adequately.
When we speak of system performance, RAM is the type of memory we refer to, so this is the type of memory used in handling ML workloads in an embedded system. The larger a system’s RAM, the more different applications it can run simultaneously because of plenty of resources to be allocated for each. However, adding more memory will not bring an increase to your system’s performance, as a single application will not eat up more memory than it requires. So, to make sure you don’t have any memory bottlenecks, define how many simultaneous programs your system will run and how much memory each of them needs. The rest will depend on the capacity of your processing unit.
Memory bandwidth is another important parameter of system memory, indicating the rate at which data can be accessed and edited, with the average bandwidth of the embedded system ranging from 128-bit to 256-bit.
- EEPROM (Electrically Erasable Programmable Read-Only Memory): this is a type of read-only memory used for keeping system configuration data that must survive power cycles but change infrequently. It ensures the system’s static functions, such as booting the device or providing instructions to run peripheral devices.
- Flash Memory: it is a modern alternative for hard drive memory that is smaller, lighter, more energy-efficient, and has a relatively fast read access time (but not faster than ROM). It is still more expensive for large-scale memory needs but is ideal for small embedded applications. Flash is mostly used in portable devices for storing program code and static data due to its mechanical shock resistance. It is also non-volatile which means it can retain data when the power is off.
Storage
Often also referred to as “memory”, computer storage is the hardware component responsible for keeping long-time application and computation data. Access and alteration to storage data by the CPU are much slower than its access to RAM, but it consumes far less power and processing capability. Storage systems come in many varieties, including flash drives, hard drives, solid state drives, SD cards, and embedded MultiMediaCard memory or eMMC.
Internal System Communication
Computer buses are communication systems responsible for transferring data between the various components of the system. While most consumer desktop computer systems have 32-bit to 64-bit buses, embedded devices have far smaller bit rates between 4-bit and 8-bit.
Drivers are responsible for communicating the software of a computer device to its hardware component. They generally run at a high privilege level in the OS run-time, and in many cases are directly linked to the OS kernel, which is a portion of an OS such as Windows, Linux, or Mac OS, which remains memory-resident and handles execution for all other code. Drivers are the messages from the OS to a specific device that facilitate the communication between the devices’ actions and the OS’s requests.
Firmware
Firmware is a type of software that serves as the intermediate between the embedded device’s hardware and business logic. Specifically, it provides the low-level control of the system’s hardware, giving it simple operation and system communication instructions, such as hardware startup, input and output tasks, or communication with other devices. Firmware is mostly installed on the device’s ROM or EEPROM for software protection and proximity to the system’s hardware and is thus never or rarely subject to any changes.
Unlike the business layer software, responsible for running the embedded application and controlling data processing and application execution workflow, the task of firmware is to interact with the hardware on one side, and the system’s OS, drivers, and middleware on the other. Also, working with this type of software requires both knowledge of programming and electronics.
Single-Board Computer
There are also such options as single-board computers (SBC) – ready-to-use, functioning mini-computer that has a microprocessor, memory, input/output interfaces, and other built-in features. The benefit of SBCs is a simple design that results in system reliability for embedded devices with fewer computer “bugs,” conflicts, and other issues that may cause downtime. However, this also entails that they have a pre-defined amount of processing power and memory and are non-configurable in case additional computing capacity is needed.
There are plenty of SBC solutions on the market, adapted to handle AI workloads on such embedded hardware systems, including:
- Nvidia Jetson Xavier NX known as the smallest AI supercomputer, boasts incredible power and energy efficiency levels at the same time and is able to handle even complex ML tasks.
- Nvidia Jetson Nano is less powerful and cheaper than Xavier NX but can be enough to process more common AI workloads.
- Raspberry Pi 4 is very affordable, widely supported, and well-documented, making it the most popular SBC globally. It easily runs the TensorFlow framework and also has a USB interface to expand its AI capabilities with the compatible Intel Neural Compute Stick 2 or Coral Edge TPU accelerator. In addition, Pi 4 offers great OS compatibility with Linux, Android, and Chrome OS, as well as non-Linux OSes.
- Google Coral Dev Board is a modular and scalable solution that can fit industrial environments, powered with Google Edge TPU co-processor for extra AI capabilities.
- Rock Pi N10 is specifically designed for AI, embedding a dedicated NPU, and is relatively inexpensive.
Sensors
The task of sensors is to gather data from the physical environment which will then be used by the system and the ML model. The inputs that a sensor responds to include temperature, ultrasound waves, light waves, pressure, or motion. The two main categories of sensors are passive and active. The former detects the radiation or signature from their targets, body heat for example. The latter emit their own radiation, ultrasound waves, or laser which get reflected from the objects and then captured by the sensor as inputs. Sensors have such characteristics as transfer function, sensitivity, span, uncertainty, noise, resolution, and bandwidth.
In embedded machine learning systems, when captured, all the sensor data is transferred to a previously trained ML model or used to train a new algorithm, if needed. Here are some of the most popular sensors used in embedded AI systems:
- Cameras that collect data for visual processing. They include:
- RGB color cameras replicate human vision and are most effective for object detection and image classification.
- Infrared cameras that collect the heat signature are widely used in autonomous vehicles for pedestrian detection, hand gesture, sign language, and facial expression recognition, as well as thermal monitoring of electrical equipment.
- Depth cameras are used to measure the exact three-dimensional depth and distance of objects with applications in quad-copter drone formation control, ripe coffee beans identification, and personal fall detection.
- 360-degree cameras that capture images or video from all directions in 3D space are used in biometric recognition, marine life research, nature photography, and navigation.
- RADAR, designed for object detection through short-pulse electromagnetic waves, is used for such tasks as military surveillance and security monitoring as well as meteorology and astronomy.
- LiDar sensors emit millions of laser waveforms and then collect their reflection to precisely measure the shape and distance of physical objects in a 3D environment. This precision makes them widely used in robotics, navigation, remote sensing, and advanced driving assistance systems.
- Microphones convert sound waves into electrical current audio signals and are mostly used for such ML tasks as speech recognition, speech source localization, and natural language processing as well as sound detection.
- Motion sensors work by making use of other sensing systems, including photosensors, angle sensors, IR sensors, optical sensors, accelerometers, inertial sensors, and magnetic bearing sensors. They keep track of a person or a physical movement thus applied for such tasks as posture detection.
Power Management
Processing AI workloads in embedded systems entails more power consumption than other tasks execution. Effective power management is particularly important for battery-powered devices, ensuring the system is optimally using its power resources. Power usage optimizations can be done both through software configurations and hardware design.
- Software power management includes such approaches as sleep mode initialization when the system hibernates to save its resources, and dynamic voltage and frequency scaling that is slowing down the CPU to lower the power consumption. Also, the quality of code which defines the number of logical CPU operations to be performed, directly impacts power consumption. Linux kernels in embedded systems can be easily customized, cutting down on running peripheral tasks.
- Hardware power management relies on hardware design with a focus on energy optimization and runtime behavioral changes for controlling power consumption. The most power-consuming elements of the embedded systems are processors and accelerators, so producers strive to make them as low-power as possible. Wireless connectivity features also add more power consumption than wired connections, so finding a tradeoff between the types of hardware interfaces in system design is another power-optimization approach.
In the context of embedded systems and machine learning, power consumption optimization strategies include three main vectors:
1. Model Design and Optimization:
- Choose energy-efficient AI models, such as lightweight convolutional neural networks or spiking neural networks with fewer parameters that require less computation
- Use pruning and quantization to remove unnecessary connections in the model and reduce the precision of calculations.
- Smaller and more energy-efficient models can be trained by transferring knowledge from a larger, pre-trained model.
- If this meets your accuracy requirements, train the model using lower precision data formats from the onset, which reduces memory usage and computational needs at inference.
2. Hardware Selection and Optimization:
- Utilize hardware specifically designed for AI workloads (discussed above).
- Adjust the voltage and clock speed of the processor based on the workload.
- Offload the AI tasks from the main processor to a more energy-efficient coprocessor designed specifically for AI functions.
3. Software Optimization:
- Make use of software libraries and frameworks specifically designed for embedded AI.
- Process data in batches instead of single instances to reduce the frequency of data transfers.
- Start low-power standby modes when the AI functionality is not actively needed, and consider power gating techniques to shut down the unused parts of the hardware.
Integrating AI in Embedded Systems
In the previous sections, we considered the software and hardware aspects of implementing Embedded Artificial Intelligence. Here, we will apply this knowledge to cover the step-by-step process of developing such systems.
Step 1: Assessment of System Requirements
Take into account that in addition to executing some common programs, such as initial startup, basic component initialization routine, and running the main programs, your system will also be loaded with AI workloads. Thus, make sure the following items are on your requirements check-list:
- Processing Power
The complexity of your machine learning model is the key factor defining the required processing capacity. The more complex your model is, the stronger the CPUs or GPUs and AI accelerators you will need. Also, note that real-time applications, for example, facial recognition in security systems, require faster processing. Meanwhile, non-real-time AI applications such as anomaly detection are more flexible in processing power requirements. - Memory
Larger models with more parameters require more memory to store during operation. Also, the amount of data your system needs to process at once will impact your memory needs. For instance, processing high-resolution images requires more memory as compared to lower-resolution ones. - Storage
First, define how much storage you’ll need for holding your trained ML model. Second, count that your system will have to store a certain amount of data for processing or buffering, especially when dealing with real-time applications. - Power Consumption
If your device is expected to be battery-powered, energy efficiency is critical for you. Use techniques for optimizing your model parameters, hardware design, and software execution to build an energy-efficient system architecture. - Connectivity
Network connectivity needs for the system, such as uploading data to the cloud or receiving updates, will define the connection protocols and ports your embedded system should include. - Sensors and Actuators
Think about how you expect your device to interact with the physical environment and consider the interfaces you’ll need for the sensors and actuators on your edge device. - Physical Form Factor
The size and weight constraints of your device will also influence the type of hardware components you can use.
This is only the list of the system aspects that can be found in any embedded project. Each application is unique and designed for different purposes, so it would be impossible to provide a comprehensive list of requirements to fit every possible use case. However, you can always reach our embedded software development experts to get professional consultation and help in defining your system requirements.
Step 2: Selection of Machine Learning Models
Today, there’s a variety of proprietary and open-source AI models you can train on your data and use for your specific applications. However, to pick the right one, you’ll need to ask yourself and answer certain questions:
- What is the application functionality the ML model should deliver, e.g. image classification, sensor data analysis, anomaly detection, behavior tracking etc.?
- What underlying ML algorithm will fit the functionality needs: decision trees, support vector machines (SVMs), or lightweight convolutional neural networks (CNNs), for instance?
- Does the application require real-time processing or can it work with some latency? What inference speed is expected?
- What is the acceptable level of model accuracy?
- What amount and type of data will the model need for training? This will impact storage and processing needs as well as model efficiency.
- What CPU, GPU, memory, storage, and power constraints should be taken into account?
- Is it possible to leverage model optimization techniques and Tiny ML tools such as TensorFlow Lite, Edge Impulse, or Arm NN?
Having answered these questions, you will understand the level of model complexity, accuracy, and speed you actually need. You’ll then be able to map these needs onto your device hardware restrictions to see whether you have to come up with additional optimization strategies.
You can take an agile iterative approach to the selection of your AI model and start with prototyping simpler and pre-trained models. This will help you quickly assess its feasibility and performance on your embedded system. You can use specialized benchmarking tools to see how different models execute on your target hardware, comparing accuracy, inference speed, and resource consumption.
Step 3: Data Preparation and Preprocessing
Once you clearly understand your application functionality and have defined the ML algorithm or model you need to work with, it’s time to get down to preparing data for it to train on.
Data Collection
Start with considering which data exactly you need to feed to your ML model and where this data will be coming from in your system – sensors, external databases, simulations, etc. If your model is designed for supervised learning and has to provide classification or prediction functionality, you will need to have your data labeled. To train your model look for hidden interconnections and insights, unsupervised learning with unlabeled data is applied. Data labeling can be automated or manual, depending on the dataset specifics. You might also need to do data cleaning and validation to make sure your model won’t be biased or erroneous.
Data Preprocessing
You might also need to use data formatting for adjusting your dataset for model training and data normalization to improve model training efficiency. We recommend splitting all your data into training, validation, and test sets to ensure you have plenty of data for each model training phase. Give priority to techniques that will minimize resource usage in your embedded AI system, for example, data compression or on-demand data fetching from the cloud. To minimize latency for real-time applications, the data preprocessing pipeline at inference has to be fast and efficient.
Data Engineering
You can apply such data engineering techniques as scaling, normalization, dimensionality reduction, and new feature creation to make raw data more informative for your model. Augmenting the training data by adding noise and diversity can help improve the ML model’s accuracy and ability to generalize. However, make sure it doesn’t become too complex for your hardware.
Step 4: Model Training and Optimization
With your training data collected and preprocessed and your model of choice at your fingertips, you can start model training. ML model training can be done in different ways: supervised and unsupervised learning.
During supervised learning, the ML algorithms are provided with labeled data, so the algorithm needs to do fewer calculations to establish correlations and rules. Such models will be less computationally complex. Supervised learning is common for training the model for classification and forecasting tasks.
In unsupervised learning, the ML algorithm is given unlabeled data for it to figure out as many implicit trends and correlations as possible. Such models will require more computational effort. They are typically applied for data clustering, recommendation engines, and drawing insights.
There’s also reinforcement learning – a methodology commonly used in robotics for skill acquisition and learning tasks. It is based on the immediate feedback or effect of the external stimuli once the system performs an action that help it learn whether it was successful or not, similar to how a small child learns the dos and don’ts. It is also said to be more computationally complex than supervised learning.
If your ML model turns out to be too complex for your needs or resources, you can resort to certain model optimization techniques:
- Model Pruning: the removal of excessive connections in the model that helps reduce the model’s complexity and memory footprint.
- Quantization: the reduction of calculation precision (e.g., from 32-bit to 8-bit) that significantly eases the memory and processing power demands.
- Knowledge Distillation: a method of training a smaller model by transferring knowledge from a larger pre-trained one. This helps to achieve plausible model accuracy with lower processing needs.
Also, as mentioned before, there are Tiny ML tools, libraries, and frameworks (TensorFlow Lite or Edge Impulse) specifically designed for adjusting ML models to the requirements of embedded AI, offering optimizations for memory usage and power management.
Step 5: Model Deployment onto the Embedded System
As the model format suitable for your embedded system can be different from the model training format, first make sure it is well-optimized to meet the hardware restrictions and converted to the appropriate format.
To run the model on your device, you will need an inference engine for loading the converted model and processing the new data with it. Popular inference engine options include TensorFlow Lite Micro, Edge Impulse runtime, or Arm NN. Also, wrapper code is needed for your system to interact with the inference engine and integrate it with the core system functionalities, for example, incoming data preprocessing at inference, passing it to the inference engine, and handling the model’s output.
For embedded devices, make sure you use a well-optimized model architecture that fits the processor capabilities, there’s enough memory allocated to store the converted model and any temporary data, and energy consumption by the model at inference is efficient.
Step 6: Security Measures
Any system that collects, processes, and stores some sort of data can be the potential goal for hackers and the source of trouble for its users or owners. This gets even more serious if it deals with sensitive data. To avoid any mishaps to the highest extent possible, taking different security measures is critical. In the context of embedded systems running AI models, we may consider three security levels.
Model Security
Machine learning models can be vulnerable to adversarial attacks where malicious actors craft inputs that cause the model to make wrong predictions. To improve the model’s robustness, you can implement adversarial training – training the model with adversarial examples.
Such techniques as digital signatures or cryptographic hashing can help you verify the integrity of the model deployed on the device and make sure the model doesn’t get tampered with by unauthorized parties.
For systems handling sensitive data, consider using privacy-preserving techniques for model training, such as federated learning and differential privacy. These approaches allow training on distributed data without compromising individual data privacy.
System Security
Secure boot mechanisms help ensure that only authorized firmware and software are loaded onto the device at startup and prevent unauthorized code execution and potential system compromise.
Secure communication protocols with encryption and authentication are must-haves if your system communicates with external servers or transmits data.
As hackers never stop looking for new system weaknesses, regular updates for the system software and the AI model itself will ensure you have all the latest security patches installed and any known vulnerabilities addressed.
Access control mechanisms will restrict unauthorized access to the system’s functionality and configuration settings.
Hardware Security
When looking for system components, check for suitable hardware that supports secure enclaves – isolated hardware execution environments – to store and execute security-sensitive code and data related to the AI model.
Tamper-evident packaging for hardware components you order helps track unauthorized physical access and prevent unwanted hardware modifications.
Step 7: Testing and Validation
When checking how our embedded machine learning system works, we can view two “phases” of testing:
- Model testing. First, this should be done as soon as we have a trained model to see how it performs on new data from the testing dataset we prepared at the data preparation stage. Using the benchmarking tools, we can compare the accuracy, speed, and resource consumption characteristics of different models (if available) that we run on the target hardware. This can be done iteratively until the optimal result is achieved.
- Integration testing. Upon model deployment and integration, it is important to make sure that the model and the rest of our embedded systems interact as expected. At this stage, we can use a simulated or real-world environment to observe the actual system performance and identify issues.
When testing embedded AI systems, make sure to take the following aspects into account:
- Edge cases and error handling must be covered to ensure the device responds adequately to unexpected inputs, invalid data, sensor malfunctions, or errors.
- For real-time applications, it is critical to test if the system meets the required processing deadlines.
- To check the model’s robustness in real-world conditions, test it using testing data with slightly different distributions compared to the training data.
- Applications with strict security requirements will make use of testing with adversarial examples – crafting malicious inputs to get the model to make wrong predictions, as well as penetration testing assessing the system’s resistance against hacking attempts.
- Performance and resource usage can be tested by measuring and monitoring memory usage and processing and energy power consumption.
- Real-world environmental factors, such as temperature variations, noise, and vibrations can have a serious impact on the embedded system’s performance, so if the device is expected to be placed in extreme environments, these should be included in the test cases list.
- If the system is designed to interact with users, it should undergo usability testing.
Step 8: Continuous Monitoring and Optimization
Continuous monitoring of the ML model’s performance in the embedded system as well as general system monitoring is key for ensuring the device’s reliability, stability, and longevity.
Data Collection and Logging
Wherever possible, strive to track the system metrics and performance indicators. For model performance, these include as accuracy, precision, recall, or inference time, helping to spot performance degradation with time. To control the system’s well-being, we can monitor memory consumption, CPU/GPU utilization, and power consumption. Logging errors or exceptions will help diagnose potential issues. To store and transmit the collected monitoring data, we can opt for on-device storage, edge storage (storage on a nearby device with more capacity), and cloud storage, depending on the system’s hardware restrictions, available resources, and general software architecture.
Monitoring Tools and Techniques
Based on the collected metrics, anomaly detection algorithms will identify deviations from normal behavior in the system and thus detect potential issues before they can significantly impact performance.
Visualization dashboards present the collected monitoring data in an easily understandable format so that you can quickly identify trends, patterns, or anomalies in system behavior.
An alerting system in place that triggers notifications when specific thresholds are crossed or anomalies are detected will enable you to address potential problems in time.
Remote Management and Updates
Secure remote access will allow for diagnostics, configuration changes, or model updates whenever needed.
With over-the-air (OTA) updates for the system software and even the AI model, you can deploy bug fixes, security patches, or improved models without physical access to the device.
Technologies for Embedded AI Systems
In the previous sections of this article, we’ve mentioned certain tools, technologies, frameworks, and libraries that help embedded systems engineers implement AI workloads on the constrained embedded architecture. Here, we provide the breakdown of top technologies that help us create performant and efficient embedded AI solutions.
Embedded AI Development Frameworks
Embedded AI development frameworks are designed to facilitate ML model training and optimization for use in embedded hardware. Quite often, such tools are provided by the developers of full-scale AI frameworks and the producers of specific-purpose hardware as packages for this hardware:
- TensorFlow Lite is a lightweight version of the TensorFlow framework for AI development in Python designed to enable AI model deployment on mobile, microcontrollers, and edge devices.
- PyTorch Mobile is a beta-stage tool for model training and deployment on mobile iOS and Android devices and edge devices.
- Apple’s Core ML is a framework optimized for the on-device performance of AI models with minimal memory footprint and power consumption on Apple hardware.
- Open VINO is Intel’s open-source visual inference and neural network optimization toolkit for easy deployment of pre-trained deep learning models on Intel architectures.
- NVIDIA JetPack is a toolkit that provides the complete development environment for building end-to-end accelerated AI applications on embedded hardware.
- MLPerf Tiny is not a development tool, it is a benchmark suite designed to ease the ML inference performance evaluation on embedded devices, offering standardized metrics and testing methodologies.
Embedded AI Computing Platforms
Embedded AI computing platforms encapsulate hardware and software designed and optimized for handling AI workloads. They provide complete ready-to-use solutions for developers and tech geeks to create and experiment with AI applications on embedded devices. Let’s consider some popular examples.
- NVIDIA Jetson is a platform offering small, power-efficient production modules with different processing power levels and developer kits suitable for high-performance acceleration for embedded AI applications, enough to power even generative AI at the edge.
- Raspberry Pi is a small computer board that provides affordable embedded AI exploration for both engineering professionals and enthusiasts. It comes in different models offering various sets of specifications and capabilities, with Raspberry Pi 5 being the most powerful and optimized for AI in the range. It is highly documented and supported and is compatible with development kits and OSes from different software providers.
- ADLINK’s Edge AI platforms come in a line of enterprise-level heterogeneous computing architecture platforms that integrate hardware acceleration in deep learning (DL) workloads, high performance per watt, end-to-end connectivity, and industrial environmental compliance for 24/7 operation.
- Mediatek Genio is a family of SoC solutions for edge AI offering a range of chipsets with variable power characteristics, energy-efficiency, modular architecture, and built-in peripherals that make them applicable for a variety of purposes and AI workloads.
If you’ve been wondering about using this technology for your business needs, we have a great article on our blog with expert advice on How to integrate GhatGPT into Your Business.
Processors for Embedded AI
In order to achieve the best performance and resource consumption efficiency in embedded systems that run AI models, hardware producers offer specific-purpose processors and microcontrollers, optimized for ML operations. Unlike general-purpose options, they provide multiple cores with higher processing power and faster clock speeds, more memory capacity, and more complex instruction set architecture (ISA) as well as readily available development tools and libraries specifically geared towards embedded AI and built-in peripherals for interfacing with sensors.
- Arm Cortex-M is a series of low-power microcontrollers (MCUs) designed for ML applications in embedded systems with dedicated instructions to execute basic machine learning operations and TensorFlow Lite included.
- NXP i.MX 8 and 9 Series is a line of multicore processors for multimedia and display applications with high-performance and low-power capabilities that offer advanced neural network processing and ML acceleration.
- Sitara AM series processors from Texas Instruments is a family of Arm-based processors optimized for vision artifical intelligence, signal processing, sensor fusion and deep learning workloads.
Hardware Accelerators for Embedded AI
While general-purpose CPUs for desktop architecture can provide enough capacity for some ML workloads, embedded systems CPUs are not recommended for running AI models on their own. Designed for general system management, they may face critical bottlenecks when used for intensive parallel computing tasks like AI inference. For this reason, it is wise to use hardware acceleration solutions that help balance the system resource consumption associated with AI in embedded systems.
The use of hardware accelerators allows to increase the system’s ML processing capabilities, harmonize memory usage, and reduce energy consumption levels. As discussed above, there are different types of hardware accelerators, such as GPUs, FPGAs, and ASICs that include TPUs and NPUs. Here are some most widely used hardware acceleration solutions on the market today:
- Intel Movidius Myriad X VPU is a dedicated AI accelerator offering high performance for computer vision and deep learning workloads on embedded devices.
- Google Coral TPU is a USB hardware accelerator that works on Linux, Mac, and Windows systems, designed to make machine learning deployment easier on embedded devices.
- Arm Ethos-U55 is a micro NPU designed to accelerate ML inference in area-constrained embedded and IoT devices and compatible with Arm’s AI-capable Cortex-M55 processor, together providing a 480x uplift in ML performance.
- IMG Series4 is the line of Imagination’s next-generation neural network accelerators designed specifically for advanced driver-assistance systems (ADAS) and autonomous vehicles.
- MTIA v1 is Meta’s first-generation recommendation-specific ASIC with integrated PyTorch. It consists of a grid of processing elements (PEs), on-chip and off-chip memory resources, and interconnects.
Communication Protocols
In an embedded system, a communication protocol is a set of rules and standards that govern data exchange between different devices or device components. These protocols define how data is formatted, transmitted, received, and acknowledged to ensure reliable, secure, and efficient communication.
The choice of communication protocols for embedded AI systems depends on several factors:
- The purpose of communication: what data needs to be exchanged, and what source it is from – the device itself, user interface commands, or a cloud server.
- Data size and frequency: large data transfers might require bandwidth-optimized protocols, while for frequent transmissions you may apply low-latency protocols.
- Power consumption: if a device is battery-powered, use protocols that can minimize energy consumption at data transmission.
- Network constraints: the communication network limitations, such as available bandwidth, latency, and reliability impact the choice of protocols.
- Security requirements: if transmissions include sensitive data, it is important to take into account encryption and authentication.
So, based on these data and network characteristics, we may define several groups of communication protocols to choose from.
- For short-range, low-power communication:
- I2C (Inter-Integrated Circuit) – low-speed protocol for communication between devices on the same board, e.g. sensors and microcontrollers.
- SPI (Serial Peripheral Interface) – faster data transfer with the support of full-duplex communication (simultaneous data send and receive), applies for communication between the main processor and peripherals, e.g. memory cards or displays.
- UART (Universal Asynchronous Receiver Transmitter) – serial communication protocol used for sending data one bit at a time, suitable for debugging or configuration purposes.
- For mid-range communication with moderate power consumption:
- CAN (Controller Area Network) – protocol designed for reliable communication between different control units within a system in harsh environments, often used in automotive and industrial automation applications.
- For longer-range communication and internet connectivity:
- WiFi – protocol for wireless networking capabilities with high bandwidth for systems that connect to a local network or the internet. Consumes more power than short-range protocols.
- Bluetooth Low Energy (BLE) – a variant of Bluetooth designed for data exchange over short to medium distances with reduced energy consumption, so is highly recommended for battery-powered devices that communicate with smartphones or other Bluetooth-enabled devices.
- Zigbee – a low-power wireless mesh network standard used for battery-powered devices within personal area networks that delivers low-latency communication.
- LoRaWAN – a low-power wide area (LPWA) wireless bi-directional networking protocol for battery-powered devices that connect to the internet in regional, national or global networks offering end-to-end security, mobility and localization services.
- For secure communication:
- HTTPS (Secure Hypertext Transfer Protocol) – a version of HTTP that offers more security with encryption.
- MQTT (Message Queuing Telemetry Transport) – a lightweight publish-subscribe messaging protocol designed for low-bandwidth and unreliable networks that can be also secured with encryption.
Conclusion
In this article, we covered the software and hardware aspects of integrating Artificial Intelligence into embedded systems, which is now becoming a more widespread practice and sought-after expertise. The benefits of the fusion of embedded systems and artificial intelligence include real-time processing speed for ML workloads, cost savings on specialized ML applications, enhanced data privacy, and more design flexibility.
The development of embedded AI systems with great functionality and performance depends on such two major factors as the choice and training of the fitting ML model and appropriate hardware selection. The choice of the ML model will highly depend on the system functions one needs to provide to end users, while hardware for such systems has to have enough capacity to handle AI workloads.
The synergy of ML models and hardware delivering a high-performance and reliable embedded AI-powered device can be achieved through the combination of several techniques:
- Model optimization using dedicated tools and frameworks commonly referred to as Tiny ML.
- System hardware architecture aimed at energy efficiency and healthy resource consumption with the use of specialized hardware.
- Keeping in mind the best practices of software development, such as iterative approach, agility, attention to data privacy and security, and continuous monitoring.
Waverley Software has been working on embedded systems and IoT development projects for many years, each followed by successful products driving our clients’ businesses and bringing value to their customers. Our team of experienced engineers, designers, and system architects can help you create the next world-changing solution embarking at any stage of your development process. Feel free to reach out to us for a technical consultation, an R&D project, end-to-end development, or standalone software services by filling out the contact form below or using our contact page.
Unlock the power of AI/ML in your embedded systems
FAQ
How AI is used in embedded systems?
AI is used in embedded systems to enhance common mechanisms and devices (e.g. robot vacuum cleaners, fridges, digital watches, traffic lights, cars) with such “smart” functions as object detection, pose and movement detection, voice recognition and natural language processing, decision making, behavior pattern detection, and predictions. In order to integrate AI into an embedded system, one has to define the type of ML model to be used, train it on relevant data, and use hardware and system design adapted to the needs of ML workloads.
What is edge AI?
Edge AI is the term that describes AI development tools, frameworks, and approaches used for optimizing ML models and deep learning neural networks for use in edge devices, which can also be referred to as embedded devices. The main advantage of edge AI over AI implemented in the cloud or a central control unit is reduced data latency, as in this case, data is being processed directly on the device and no time loss for data travel takes place.
What is the primary benefit of integrating machine learning into embedded systems?
The use of machine learning in embedded systems has several advantages:
- Real-time data analytics and system response with minimal latency.
- Increased data security without the need for transferring data elsewhere from the device.
- Cost savings on cloud infrastructure for AI workloads.
- Design flexibility due to the wide range of hardware and software options on the market.
How do I choose the right machine learning model for my embedded system?
To choose the ML model that will fit your embedded system, one needs to take several steps:
- Analyze the user needs your system is designed to meet, the functionality it is aimed to deliver, and the available resources.
- Study the available ML algorithms to find out which one can provide the needed function. For example, the Linear Regression algorithm will be a good fit for forecasting tasks, the Support Vector Machines algorithm is used for classification tasks, the Naive Bayes algorithm is designed for text categorization, and so on.
- Based on the ML algorithm options you can use, your future application needs, and the hardware you can afford, define the optimal model complexity you can expect and the model accuracy and speed you will have to develop.
- Collect and prepare the relevant data for training your model, and split it into training and testing data.
- Train your model using the training data set.
- Test and verify your model training results using the training data set. Make adjustments in data or model parameters, if needed, and start over the training phase.
- Once the model starts providing expected results on yet unseen data, it’s ready for integration into your embedded system and testing within.







