From being a cost-cutting measure, cloud computing has developed into a key component. Artificial intelligence has made a significant shift from cloud computing to physical systems. Devices, from consumer electronics to industrial sensors, are becoming decision-making agents rather than merely passive data gatherers.
Performance is only one aspect of this progression; another is where intelligence lies.
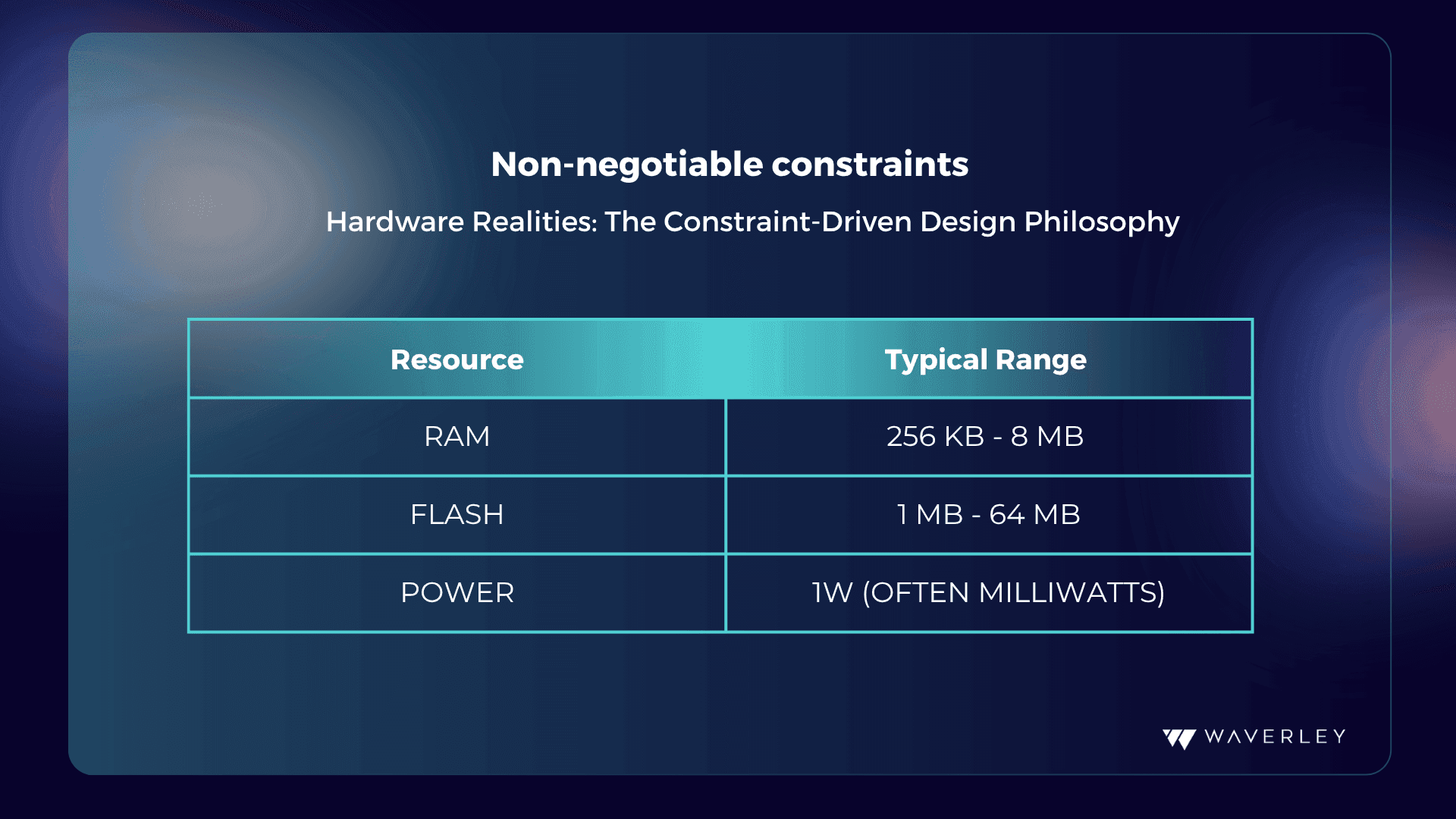
The usual definition of embedded AI must be considered to understand this change. According to our previous Embedded AI Systems Guide (2024), embedded AI is the direct incorporation of machine learning models into hardware-constrained systems, allowing devices to carry out tasks like perception, prediction, and decision-making without requiring continuous cloud connectivity. Typically, these systems integrate sensors, processors, memory, and software into tightly integrated architectures tailored to specific use cases, such as consumer electronics, healthcare, and industrial automation.
Although the design, optimization, and deployment of these systems have changed dramatically due to advancements in edge computing, hardware acceleration, and real-time AI capabilities, this foundation is still applicable today.
Over 70% of AI workloads are anticipated to run at the edge in the next few years due to latency, privacy, and bandwidth limitations, according to a 2026 market outlook from Edge AI and Vision Alliance.
Simultaneously, semiconductor companies such as NVIDIA, Qualcomm, and ARM are integrating AI accelerators directly into their chipsets.
In simple terms:
If your system interacts with the physical world, it will likely require embedded AI.
This functionality was frequently restricted to specific tasks like anomaly detection, image classification, or signal processing in older versions. Nevertheless, these systems were usually built around static models with little adaptability, as explained in earlier embedded AI frameworks, demonstrating how far modern architectures have come toward dynamic and context-aware intelligence.